Hive的压缩格式与数据存储格式 优化数据处理与存储服务
在大数据生态系统中,Apache Hive作为基于Hadoop的数据仓库工具,广泛应用于数据查询、分析和处理。其数据处理效率与存储成本直接受到压缩格式和存储格式的影响。合理选择压缩和存储格式,可以显著提升查询性能、降低存储开销,并优化数据处理与存储服务。
一、Hive的数据存储格式
数据存储格式决定了数据在HDFS上的组织方式,影响读写速度、压缩效率和查询性能。常见的存储格式包括:
- 文本格式(TextFile):
- 默认格式,以纯文本形式存储,如CSV或JSON。
- 优点:人类可读,兼容性好。
- 缺点:存储空间大,查询性能低,不支持分片。
- 序列文件格式(SequenceFile):
- 二进制键值对存储格式,适用于MapReduce作业。
- 优点:支持分片和压缩,适合小文件合并。
- 缺点:非列式存储,查询效率有限。
- 列式存储格式:
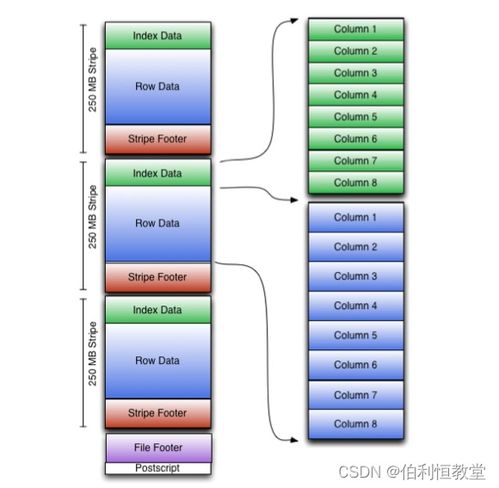
- ORC(Optimized Row Columnar):Hive原生格式,结合行和列存储优势,支持索引、压缩和谓词下推,大幅提升查询速度。
- Parquet:跨平台列式存储格式,兼容Spark、Impala等工具,支持高效压缩和嵌套数据结构。
- 优点:仅读取查询所需的列,减少I/O;高压缩比;适合聚合查询。
- 适用场景:数据仓库、分析型负载。
- Avro格式:
- 基于JSON模式的二进制格式,支持数据序列化和动态模式演化。
- 优点:模式与数据一起存储,兼容性好,适合数据交换。
- 缺点:查询性能不如列式格式。
二、Hive的压缩格式
压缩格式用于减少存储空间和网络传输开销,但可能增加CPU计算负载。Hive支持多种压缩编解码器:
- Gzip:
- 压缩率高,但压缩和解压速度较慢,不支持分片。
- 适合冷数据存储或对存储空间敏感的场景。
- Snappy:
- 压缩速度极快,压缩率适中,支持分片(与存储格式结合时)。
- 适合需要快速读写的数据处理管道,如实时分析。
- LZO:
- 压缩速度与Snappy类似,支持分片,但需额外索引文件。
- 适用于Hadoop生态中的中间数据存储。
- Bzip2:
- 压缩率最高,但速度最慢,CPU消耗大。
- 适合归档存储,极少用于生产查询。
三、压缩与存储格式的搭配优化
在实际数据处理与存储服务中,需根据业务需求平衡性能、存储和兼容性:
- 高性能查询场景:建议使用ORC或Parquet格式,搭配Snappy压缩。列式存储减少I/O,Snappy提供快速解压,适合交互式查询。
- 高压缩存储场景:选择ORC格式(或Parquet)搭配Zlib(或Gzip)压缩,显著降低存储成本,适用于历史数据归档。
- 数据交换与兼容场景:Avro格式搭配Snappy压缩,确保模式灵活性和传输效率。
- 实时处理流水线:可选用Parquet+Snappy,兼顾分析性能和写入速度。
四、实践建议
- 测试驱动选择:在部署前,使用实际数据集测试不同组合的查询速度、压缩比和资源消耗。
- 分区与分桶:结合存储格式,合理设计分区和分桶策略,进一步提升查询效率。
- 监控与调整:持续监控集群性能,根据数据增长和查询模式调整格式与压缩策略。
###
Hive的压缩格式和数据存储格式是构建高效数据处理与存储服务的核心要素。通过深入理解各类格式的特性,并结合业务场景进行优化组合,企业可以显著提升大数据平台的处理能力,同时控制成本,为数据分析与决策提供坚实基础。
如若转载,请注明出处:http://www.pyweimob.com/product/21.html
更新时间:2026-06-19 15:45:36